Adding search functionality to a site can be deceptively complex. There's a lot more than just basic string matching that goes into a decent search function -- e.g. fuzziness, stemming, synonyms, etc. Luckily, there are several software services available that provide a lot of functionality out-of-the-box. I'm currently a fan of Elasticsearch for its ease of use and feature-set.
Elasticsearch provides two .NET clients: both a low-level .NET client, Elasticsearch.net, as well as their high-level client, NEST. This post is about using NEST with ASP.NET. NEST is quite powerful, and easy to get into. Note that there's also a sample working .NET 7 project in C# that goes along with these code examples.
There are several terms around search that are important, and can improve your search performance if you apply them thoughtfully to your fields:
- Fuzziness - not every search term will be spelled or typed exactly like the words that are indexed. Making a query fuzzy means that it will match results that aren't spelled exactly the same. E.g., you probably want to return results for matrix when the user has typed matrx. Elasticsearch supports a number of options, such as edit distance, which is based on the number of single character edits to a string, as well as phonetic fuzziness where a term may be misspelled, but the misspelling sounds like the correct spelling. We'll show an example of a fuzzy search below.
- Stemming - the process of reducing words to their base, or stem. Your text will typically use multiple forms of a word. E.g., learn, learned, learning. You may want a query for any of the forms to match any of the others. So a query for learning can return results that have learn and learned in them. Elasticsearch has multiple options here, from algorithmic stemmers that automatically determine word stems, to dictionary stemmers. Stemming can also decrease index size by storing only the stems, and thus, fewer words. We'll show an example of using algorithmic stemmers below.
- Stop Words - these are words that aren't used in the index. Commonly used, short words that don't add additional meaning to sentences are commonly used as stop words. E.g., a, and, the, or. Somewhat similarly to stemming, using stop words can improve the size and performance of indices by limiting the number of words stored. Elasticsearch has some built-in stop word lists, and we'll show the use of one below.
- Synonyms - to produce better search results, you can also define lists of synonyms for Elasticsearch. Synonyms are what they sound like -- words that have the same or nearly the same meanings. E.g., you may want a query for huge to bring back results that have big in them. Synonyms can also be particularly useful with industry terms. We'll show an example of using synonyms below.
Let's get started -- the example below is pretty simple, and we're going to use small objects that describe books and their objects. With NEST, you need to map your objects. The mapping can be inferred, or you can use attribute mapping or a fluent API with NEST. Note that you must use AutoMap() as we do below when using attribute mapping. I personally prefer to decorate classes with attributes, and it's a similar pattern to data annotations:
public enum BookGenre
{
None = 0,
Adventure,
Biography,
Drama,
HistoricalFiction,
Science
}
[ElasticsearchType(RelationName = "author")]
public class Author
{
public string FirstName { get; set; }
public string LastName { get; set;}
}
[ElasticsearchType(RelationName = "book", IdProperty = nameof(Id))]
public class Book
{
public int Id { get; set; }
public Author Author { get; set; }
[Text(Boost = 1.5)]
public string Title { get; set; }
public string Opening { get; set; }
[StringEnum]
public BookGenre Genre { get; set; }
[Ignore]
public int InitialPublishYear { get; set; }
}Couple things to note here: We've specified our Id field for our Book class, and you can use this to change what's used as an id in your index. We've also specified the type on our Title field, though NEST could have already figured out that string maps to Text -- the interesting thing here is that we're also boosting the field, which means it will be more important and count towards more of the score when we search against this data. (We're basically assuming the Title is the most important piece of the text here.) On the enumerated type, we're using [StringEnum] which tells NEST to serialize the enumerated values as strings, e.g. ""Adventure", "Biography", etc. If we didn't do this, it would store those as "1", "2", "3", etc. in the index. Finally, we're using [Ignore] to remove a field from serialization and not use it in our index.
Next we'll create an extension that you can use to add the client to the services collection for dependency injection:
public static class ElasticsearchExtensions
{
public static void AddElasticsearch(this IServiceCollection services, IConfiguration configuration)
{
var settings = new ConnectionSettings(new Uri(configuration["ElasticsearchSettings:uri"]));
var defaultIndex = configuration["ElasticsearchSettings:defaultIndex"];
if (!string.IsNullOrEmpty(defaultIndex))
settings = settings.DefaultIndex(defaultIndex);
var client = new ElasticClient(settings);
services.AddSingleton<IElasticClient>(client);
}
}The ElasticClient is thread-safe, so Singleton is the correct pattern here. There are also quick code examples for ApiKey and BasicAuth in the linked code sample.
Your appsettings.json might then look something like this for the Uri of your Elasticsearch instance and your default index:
{
"ElasticsearchSettings": {
"uri": "http://localhost:9200/",
"defaultIndex": "books"
}
}We also need to create our index to search against in Elasticsearch. We could put this in our ElasticsearchExtensions class, but it might take a little longer to run. So, we really want it to run asynchronously when the application starts up. To do that, we create a class that implements IHostedService:
public class ElasticsearchHostedService : IHostedService
{
private readonly IElasticClient _elasticClient;
public ElasticsearchHostedService(IElasticClient elasticClient)
{
_elasticClient = elasticClient;
}
public async Task StartAsync(CancellationToken cancellationToken)
{
var booksIndexName = "books";
// The check for whether this index exists and subsequently deleting
// it if it does is for demo purposes! This is so we can make changes
// in our code and have them reflected in the index. In production,
// you would not want to do this.
if ((await _elasticClient.Indices.ExistsAsync(booksIndexName)).Exists)
await _elasticClient.Indices.DeleteAsync(booksIndexName);
var createMoviesIndexResponse = await _elasticClient.Indices.CreateAsync(booksIndexName, c => c
.Settings(s => s
.Analysis(a => a
.TokenFilters(tf => tf
.Stop("english_stop", st => st
.StopWords("_english_")
)
.Stemmer("english_stemmer", st => st
.Language("english")
)
.Stemmer("light_english_stemmer", st => st
.Language("light_english")
)
.Stemmer("english_possessive_stemmer", st => st
.Language("possessive_english")
)
.Synonym("book_synonyms", st => st
// If you have a lot of synonyms, it's probably better to create a synonyms
// text file and use .SynonymsPath here instead.
.Synonyms(
"haphazard,indiscriminate,erratic",
"incredulity,amazement,skepticism")
)
)
.Analyzers(aa => aa
.Custom("light_english", ca => ca
.Tokenizer("standard")
.Filters("light_english_stemmer", "english_possessive_stemmer", "lowercase", "asciifolding")
)
.Custom("full_english", ca => ca
.Tokenizer("standard")
.Filters("english_possessive_stemmer",
"lowercase",
"english_stop",
"english_stemmer",
"asciifolding")
)
.Custom("full_english_synopsis", ca => ca
.Tokenizer("standard")
.Filters("book_synonyms",
"english_possessive_stemmer",
"lowercase",
"english_stop",
"english_stemmer",
"asciifolding")
)
)
)
)
.Map<Book>(m => m
.AutoMap()
.Properties(p => p
.Text(t => t
.Name(n => n.Title)
.Analyzer("light_english")
)
.Text(t => t
.Name(n => n.Opening)
.Analyzer("full_english_synopsis")
)
)
)
);
}
public Task StopAsync(CancellationToken cancellationToken) => Task.CompletedTask;
}There area couple things to unpack here:
- The first thing to note is that we're always deleting and recreating the index when the app starts. This makes it easy to test, since we can make changes to the data or indexing that only happen when documents are indexed. However, this is something you really don't want to do in a real production app.
- Our index creation call is roughly split into three sections: setting up some filters to use in
Settings.Analysis, creating analyzers that use them inSettings.Analyzers, and then making use of them when we map our object. - Under our
TokenFilterssection, we're setting up some of the things we briefly mentioned above: aStopWordsfilter, a coupleStemmers("light_english" is less aggressive than "english"), and ourSynonymlist. - At the bottom of
StartAsync, we're doing the most important bit, which is callingAutoMapto make use of the attribute mapping we applied on our data classes above, and then applyingAnalyzersthat we set up immediately before. We're letting the defaults take effect for the rest of the fields, but we're setting the more aggressiveAnalyzer(with the "english" stemmer and making use of our "book_synonyms") on theOpeningfield, and the more straightforwardAnalyzeron theTitlefield.
Then, in our Startup.cs, we're going to make use of our extension and hosted service:
public void ConfigureServices(IServiceCollection services)
{
// Add the configured ElasticClient to our service collection
services.AddElasticsearch(Configuration);
// Add our hosted service which will create our indices and mapping
// asynchronously on startup
services.AddHostedService<ElasticsearchHostedService>();
services.AddControllersWithViews();
}For demonstration purposes, we've also added some static values into Index() on HomeController.cs where we have a few Book items which we'll insert into our index (the examples below are excerpts from books that are in the public domain; you can download them from many places such as the Digital Public Library of America):
public async Task<IActionResult> Index()
{
var books = new List<Book>()
{
new Book
{
Id = 1,
Title = "Narrative of the Life of Frederick Douglass",
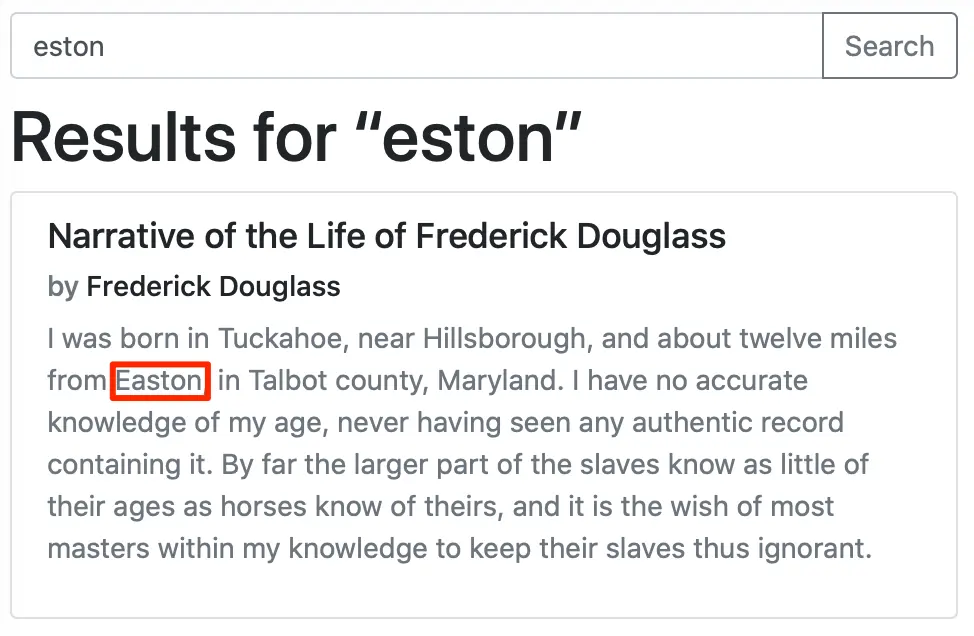
Opening = "I was born in Tuckahoe, near Hillsborough, and about twelve miles from Easton, in Talbot county, Maryland. I have no accurate knowledge of my age, never having seen any authentic record containing it. By far the larger part of the slaves know as little of their ages as horses know of theirs, and it is the wish of most masters within my knowledge to keep their slaves thus ignorant.",
Genre = BookGenre.Biography,
Author = new Author
{
FirstName = "Frederick",
LastName = "Douglass"
},
InitialPublishYear = 1845
},
new Book
{
Id = 2,
Title = "A Tale of Two Cities",
Opening = "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way—in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.",
Genre = BookGenre.HistoricalFiction,
Author = new Author
{
FirstName = "Charles",
LastName = "Dickens"
},
InitialPublishYear = 1859
},
new Book
{
Id = 3,
Title = "On the Origin of Species",
Opening = "When we compare the individuals of the same variety or sub-variety of our older cultivated plants and animals, one of the first points which strikes us is, that they generally differ more from each other than do the individuals of any one species or variety in a state of nature. And if we reflect on the vast diversity of the plants and animals which have been cultivated, and which have varied during all ages under the most different climates and treatment, we are driven to conclude that this great variability is due to our domestic productions having been raised under conditions of life not so uniform as, and somewhat different from, those to which the parent species had been exposed under nature.",
Genre = BookGenre.Science,
Author = new Author
{
FirstName = "Charles",
LastName = "Darwin"
},
InitialPublishYear = 1859
},
new Book
{
Id = 4,
Title = "Oh Pioneers!",
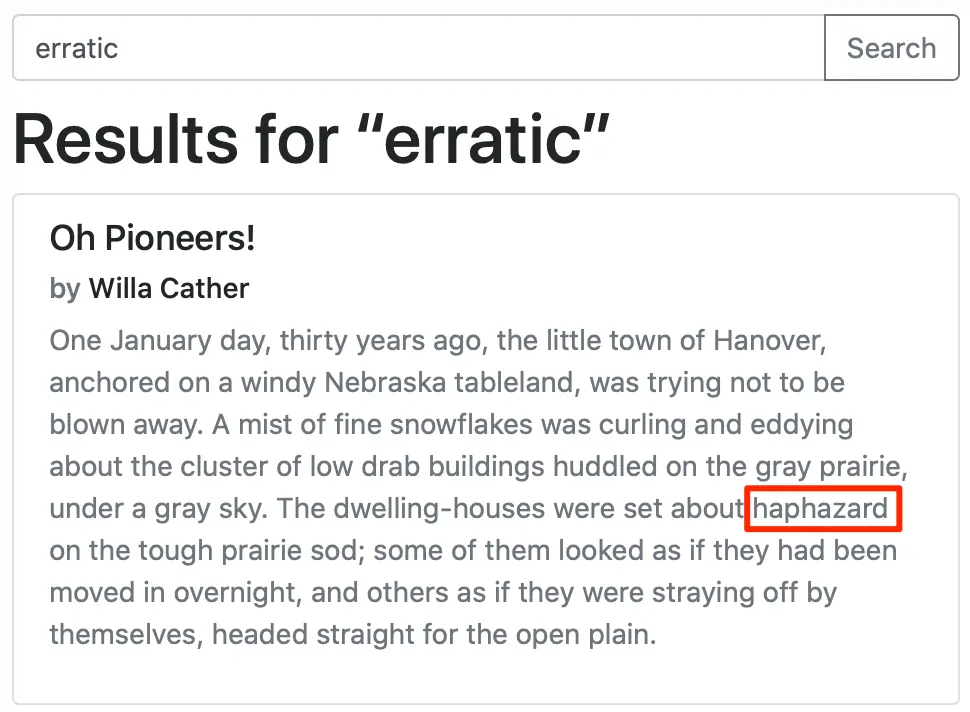
Opening = "One January day, thirty years ago, the little town of Hanover, anchored on a windy Nebraska tableland, was trying not to be blown away. A mist of fine snowflakes was curling and eddying about the cluster of low drab buildings huddled on the gray prairie, under a gray sky. The dwelling-houses were set about haphazard on the tough prairie sod; some of them looked as if they had been moved in overnight, and others as if they were straying off by themselves, headed straight for the open plain.",
Genre = BookGenre.HistoricalFiction,
Author = new Author
{
FirstName = "Willa",
LastName = "Cather"
},
InitialPublishYear = 1913
},
new Book
{
Id = 5,
Title = "Moby Dick",
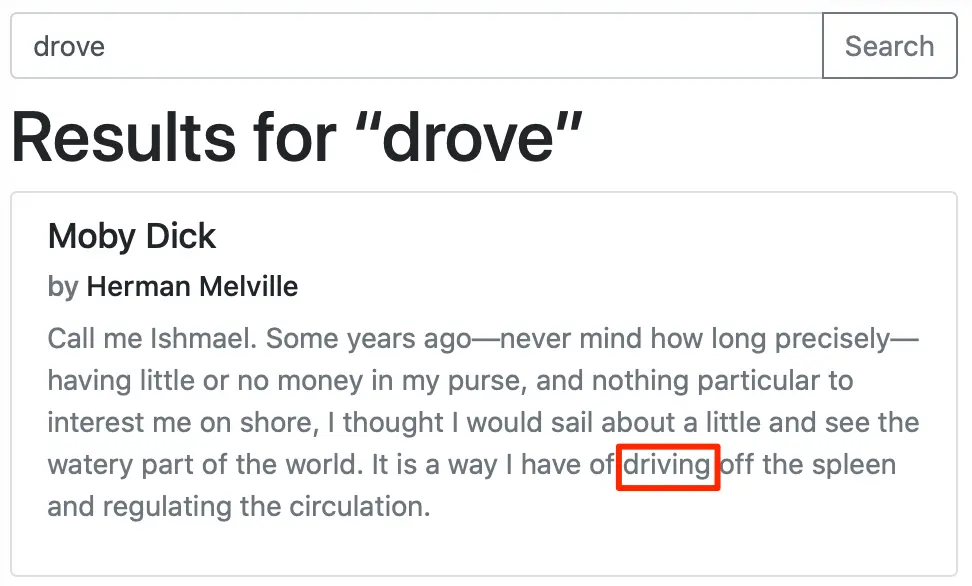
Opening = "Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world. It is a way I have of driving off the spleen and regulating the circulation.",
Genre = BookGenre.Adventure,
Author = new Author
{
FirstName = "Herman",
LastName = "Melville"
},
InitialPublishYear = 1851
}
};
foreach (var book in books)
{
var existsResponse = await _elasticClient.DocumentExistsAsync<Book>(book);
// If the document already exists, we're going to update it; otherwise insert it
// Note: You may get existsResponse.IsValid = false for a number of issues
// ranging from an actual server issue, to mismatches with indices (e.g. a
// mismatch on the datatype of Id).
if (existsResponse.IsValid && existsResponse.Exists)
{
var updateResponse = await _elasticClient.UpdateAsync<Book>(book, u => u.Doc(book));
if (!updateResponse.IsValid)
{
var errorMsg = "Problem updating document in Elasticsearch.";
_logger.LogError(updateResponse.OriginalException, errorMsg);
throw new Exception(errorMsg);
}
}
else
{
var insertResponse = await _elasticClient.IndexDocumentAsync(book);
if (!insertResponse.IsValid)
{
var errorMsg = "Problem inserting document to Elasticsearch.";
_logger.LogError(insertResponse.OriginalException, errorMsg);
throw new Exception(errorMsg);
}
}
}
var vm = new HomeViewModel
{
InsertedData = JsonConvert.SerializeObject(books, Formatting.Indented)
};
return View(vm);
}Above, we're checking whether the Book already exists in the index, and updating it if it does, or inserting it, if not. We're then converting our object list to Json to display to the user if they're using the sample application.
And we've implemented a basic search in our SearchController.cs:
[HttpGet]
public async Task<IActionResult> Index(string q)
{
if (string.IsNullOrEmpty(q))
{
var noResultsVM = new SearchViewModel { Term = "[No Search]" };
return View(noResultsVM);
}
var response = await _elasticClient.SearchAsync<Book>(s =>
s.Query(sq =>
sq.MultiMatch(mm => mm
.Query(q)
.Fuzziness(Fuzziness.Auto)
)
)
);
var vm = new SearchViewModel
{
Term = q
};
if (response.IsValid)
vm.Results = response.Documents?.ToList();
else
_logger.LogError(response.OriginalException, "Problem searching Elasticsearch for term {0}", q);
return View(vm);
}There's a good comparison of the types of queries available on qbox.io. Here we're using MultiMatch, and the other important thing here is that we're using Fuzziness(Fuzziness.Auto) to make this a fuzzy search.
Let's see some examples from our sample application:
Check out the sample application on GitHub at https://github.com/adam-russell/elasticsearch-aspnet-core-sample. Feel free to let me know if you notice any bugs or omissions.